بهترین و جدید ترین پروژه - تحقیق - پایان نامه
پروژه - تحقیق - پایان نامهبهترین و جدید ترین پروژه - تحقیق - پایان نامه
پروژه - تحقیق - پایان نامهپروژه انواع تکنیک های داده کاوی

پروژه انواع تکنیک های داده کاوی
فرمت فایل دانلودی: .docxفرمت فایل اصلی: docx
تعداد صفحات: 63
حجم فایل: 1251
قیمت: : 7000 تومان
بخشی از متن:
چکیده:
امروزه به دلیل وجود ابزارهای مختلف برای جمع آوری داده ها و پیشرفت قابل قبول تکنولوژی پایگاه داده حجم انبوهی از اطلاعات در انبار داده های مختلف ذخیره شده است. این رشد انفجاری داده ها، احتیاج به یک سری تکنیک ها و ابزارهای جدید که توانایی پردازش هوشمندانه اطلاعات را دارا باشند، نمایان می سازد. با استفاده ار پرسش های ساده در SQL و ابزارهای گوناگون گزارش گیری معمولی، می توان اطلاعاتی را در اختیار کاربران قرار داد تا بتوانند به نتیجه گیری در مورد داده ها و روابط منطقی میان آنها بپردازند اما وقتی که حجم داده ها بالا باشد، کاربران هر چقدر حرفه ای و با تجربه باشند نمی توانند الگوهای مفید را در میان حجم انبوه داده ها تشخیص دهند و یا اگر قادر به این کار هم باشند، هزینه عملیات از نظر نیروی انسانی و مالی بسیار بالا است.
در حال حاضر داده کاوی در پایگاه داده های بزرگ، توسط بسیاری از محققان به عنوان یک موضوع تحقیقاتی مهم به شمار می آید. محققان در بسیاری از رشته ها نظیر پایگاه داده ها، یادگیری ماشین و آمار این موضوع را پیگیری کرده و تکنیک های مختلفی را در این زمینه ارائه دادند. داده کاوی یکی از مهمترین روشهایی است که به وسیله آن الگوهای مفید در داده ها با حداقل دخالت کاربران شناخته می شوند و اطلاعاتی را در اختیار کاربران و تحلیل گران قرار می دهند تا براساس آنها تصمیمات مهم و حیاتی در سازمان ها اتخاذ شوند. در داده کاوی از بخشـی به نام تحلیل اکتشــافی داده ها استفاده می شود که در آن بر کشف اطلاعات نهفته و ناشناخته از درون حجم انبوه داده ها تاکید می شود بنابراین می توان گفت در داده کاوی تئوری های پایگاه داده ها، هوش مصنوعی، یادگیری ماشین وعلم آمار را در هم می آمیزند تا زمینه کاربردی فراهم شود. مراحل مختلف استخراج دانش در پایگاه داده ها:
- درک دامنه مسئله
- استخراج یک مجموعه داده
- آماده سازی و پاک سازی
- یکپارچه سازی داده ها
- کاهش و تغییر شکل داده ها
- انتخاب نوع کاوش داده ها
- انتخاب الگوریتم کاوش داده ها
- استفاده از دانش کشف شده
فهرست مطالب:
چکیده
1. مقدمه
1-1. تاریخچه
2. داده کاوی
2-1. مفاهیم اساسی در داده کاوی
2-2. جایگاه دادهکاوی
2-3. بعضی از کابردهای داده کاوی
3. مراحل داده کاوی
3-1. مرحله اول شناخت کسب و کار
3-2. مرحله دوم شناخت اطلاعات
3-2-1. جمع آوری داده های اولیه و اصلی
3-2-2. شرح وتوصیف داده ها
3-2-3. کاوش داده ها
3-2-4. تحقیق در مورد کیفیت داده ها
3-3. مرحله سوم آماده سازی داده ها
3-3-1. انتخاب داده ها
3-3-2. تمیز کردن داده ها
3-3-3. تبدیل داده ها
3-3-4. تلفیق داده ها
3-4. مرحله چهارم مدلسازی
3-4-1. استقرار مدل ها
3-5. مرحله پنجم ارزیابی
3-5-1. ارزیابی مدل های توصیفی
3-5-2. ارزیابی مدل های جهتدار
3-5-3. ارزیابی طبقه بندها و پیشگوها
3-5-4. ارزیابی تخمینگرها
3-6. مرحله ششم پیاده سازی
3-6-1. گسترش برنامه
3-6-2. نگهداری و قوت برنامه
3-6-3. تولیدگزارش نهایی
3-6-4. تجدید نظر و نشریه کردن پروژه
4. استراتژیهای دادهکاوی
4-1. یادگیری با نظارت یا یادگیری تحت نظارت
4-2. یادگیری بدون نظارت
5. تکنیکهای دادهک اوی
5-1. طبقه بندی
5-2. خوشه بندی
5-2-1. نقطه تمایز خوشه بندی از دسته بندی
5-3. رگرسیون گیری
5-3-1. رگرسیون منطقی
5-4. تجمع وهمبستگی
5-5. درخت تصمیم گیری
5-5-1. اهداف اصلی درختهای تصمیم گیری دسته بندی کننده
5-5-2. گامهای لازم برای طراحی یک درخت تصمیم گیری
5-5-3. جذابیت درختان تصمیم
5-5-4. بازنمایی درخت تصمیم
5-5-5. مسائل عملی در یادگیری درختان تصمیم
5-5-6. اورفیتینگ داده ها
5-5-7. انواع روشهای هرس کردن
5-5-8. مزایا و معایب درختان تصمیم
5-6. الگوریتم ژنتیک
5-6-1. مزایا و معایب الگوریتم های ژنتیک
5-7. شبکه های عصبی
5-7-1. شبکه عصبی با یک لایه نهان
5-7-2. مزایا و معایب شبکههای عصبی
5-7-3. کاربردها
5-7-4.معماری شبکه عصبی مصنوعی
6. گام نهایی فرایند داده کاوی
7. تکنولوژی های مرتبط با داده کاوی
7-1. انبارداده
7-1-1. مشخصات ساختاری انبارداده
7-2. OLAP
8. وظایف داده کاوی
8-1. دسته بندی
8-2. خوشه بندی
8-3. تخمین
8-4. وابستگی
8-5. رگرسیون
8-6. پیشگویی
8-7. تحلیل توالی
8-8. تحلیل انحراف
8-9. نمایه سازی
9. محدودیتهای داده کاوی
10. نرم افزارهای داده کاوی
10-1. نرم افزار وکا
10-1-1. قابلیتهای وکا
10-2. نرم افزار JMP
10-2-1. قابلیتهای JMP
11. نتیجه گیری
12. منابع
 پرداخت با کلیه کارتهای عضو شتاب امکان پذیر است.
پرداخت با کلیه کارتهای عضو شتاب امکان پذیر است.پایان نامه بررسی تاثیر تنیدگی بر افراد سالم و افراد متبلا به بیماری میگرن

پایان نامه بررسی تاثیر تنیدگی بر افراد سالم و افراد متبلا به بیماری میگرن
فرمت فایل دانلودی: .docفرمت فایل اصلی: doc
تعداد صفحات: 91
حجم فایل: 296
قیمت: : 18000 تومان
بخشی از متن:
چکیده:
پژوهش حاضر به دنبال بررسی تاثیر تنیدگی در افراد سالم و افراد مبتلا به بیماری میگرن در تهران می باشد. فرضیه هایی که به معرض آزمایش گذشته شدند عبارتند از:
فرضیه اول: مقایسه تاثیر تنیدگی بر افراد سالم و افراد مبتلا به میگرن و فرضیه دوم: مقایسه تاثیر تنیدگی در بین زنان و مردان دارای سردردهای میگرنی!
گروه نمونه ی این پژوهش شامل 60 نفر از افرادی هستند که 30 نفر افراد سالم و 30 نفر افراد مبتلا به سردردهای میگرنی می باشد که به صورت تصادفی انتخاب شده اند و بر روی آنها آزمون استرس انجام شد که پس از آن از روش (t) استفاده شده که نتیجه بدست آمده به شرح زیر می باشد:
- تاثیر تنیدگی بر افراد مبتلا به بیماری میگرن بیشتر می باشد.
- تاثیر تنیدگی بر زنان میگرنی بیشتر ا ز مردان میگرنی است.
فهرست مطالب:
چکیده
فصل اول: کلیات
مقدمه
طرح مساله
اهداف پژوهش
ضرورت تحقیق
فصل دوم: نگاهی به تاریخچه های پژوهش
مقدمه
ادبیات تحقیق (استرس)
پیشینه نظری (استرس)
تعریف سردرد های میگرنی
انواع سردرد
سردرد شریانی از نوع میگرن
تعریف میگرن (تاریخچه)
نشانه های میگرن
میگرن چند مرحله دارد
فراوانی سردرد میگرن
انواع مختلف میگرن
میگرن کلاسیک
میگرن چشمی
میگرن بازیلر
میگرن یائسکی
علت شناسی
اختلالات عروق مغز
احتلالات زیست- شیمیایی
خواب
عوامل روانشناختی
تشخیص اختراقی
درمان گری میگرن
سایر روشهای درمان گری
پیشینه تحقیق
تحقیقات صورت گرفته در خارج از ایران
تحقیقات صورت گرفته در ایران
فصل سوم: روش تحقیق
مقدمه
جمعیت هدف
روش اجرا
روش آماری
فصل چهارم: یافته ها و تجزیه و تحلیل داده ها
مقدمه
یافته ها و تجریه و تحلیل داده ها
فصل پنجم: بحث و نتیجه گیری
نتیجه گیری
بحث درمورد یافته های تحقیق
محدودیت ها و پیشنهادات
پیشنهادات
منابع
ضمائم
پرداخت با کلیه کارتهای عضو شتاب امکان پذیر است.
تحقیق تفسیر سوره حمد از دیدگاه مفسرین شیعه و اهل سنت
فرمت فایل دانلودی: .docxفرمت فایل اصلی: docx
تعداد صفحات: 23
حجم فایل: 169
قیمت: : 23000 تومان
بخشی از متن:
بخشی از متن:
فصلی در فضل فاتحه الکتاب، این فصل نبشته شد تا رغبت خواننده در خواندن و دانستن آن بیفزاید. حجه الاسلام محمد غزالی، قدس الله روح العزیز، در کتاب جواهر القرآن می گوید: که غرض فرستادن پیغامبران آن بود که خلق را از خود به حق خوانند و این غرض به بیان ده چیز تمام شود: ....
فهرست مطالب:
فضائل سوره فاتحه الکتاب
التفسیر الکبیر- الباب الثانی فی فضائل هذه السوره
اسامی این سوره
نکاتی در مورد بِسْمِ اللَّهِ الرَّحْمَنِ الرَّحِیمِ
نتیجه
الْحَمْدُ للّهِ رَبِّ الْعَالَمِینَ
الرَّحْمنِ الرَّحِیمِ
مَالِکِ یَوْمِ الدِّینِ
إِیَّاکَ نَعْبُدُ وإِیَّاکَ نَسْتَعِینُ
اهدِنَا الصِّرَاطَ المُستَقِیمَ
صراط مستقیم چیست ؟
صِرَاطَ الَّذِینَ أَنعَمتَ عَلَیهِمْ
غَیرِ المَغضُوبِ عَلَیهِمْ وَلاَ الضَّالِّینَ
منابع
پرداخت با کلیه کارتهای عضو شتاب امکان پذیر است.پروژه تشخیص هوشمند حالت افراد از روی تصاویر با استفاده از تکنیک های پردازش تصویر
پروژه تشخیص هوشمند حالت افراد از روی تصاویر با استفاده از تکنیک های پردازش تصویر
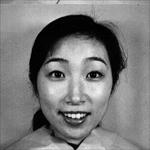 پروژه متلب تشخیص هوشمند حالت افراد از روی تصاویر با استفاده از تکنیک های پردازش تصویر، تشخیص حالت افراد از روی چهره، تشخصی حالتهای مختلف نگرانی، عصبانیت، خوشحالی، استرس و ... با استفاده از الگوریتم هوشمند در برنامه شناسایی می گردد. این پروژه شبیه سازی یک مقاله می باشد.
پروژه متلب تشخیص هوشمند حالت افراد از روی تصاویر با استفاده از تکنیک های پردازش تصویر، تشخیص حالت افراد از روی چهره، تشخصی حالتهای مختلف نگرانی، عصبانیت، خوشحالی، استرس و ... با استفاده از الگوریتم هوشمند در برنامه شناسایی می گردد. این پروژه شبیه سازی یک مقاله می باشد.
پروژه پردازش صوت در متلب (شبیه سازی مقاله ieee)
پروژه پردازش صوت در متلب (شبیه سازی مقاله ieee)
 پروژه پردازش صوت در متلب، شبیه سازی مقاله Wavelet-Based Statistical Signal Processing Using Hidden Markov Models، پردازش صوت در متلب با استفاده از مدل مخفی مارکوف، ضمنا از تبدیل ویولت در این مقاله استفاده می گردد.
پروژه پردازش صوت در متلب، شبیه سازی مقاله Wavelet-Based Statistical Signal Processing Using Hidden Markov Models، پردازش صوت در متلب با استفاده از مدل مخفی مارکوف، ضمنا از تبدیل ویولت در این مقاله استفاده می گردد.
پروژه کنترل فازی بر روی مدل توپ و میله
پروژه کنترل فازی بر روی مدل توپ و میله
 پروژه رشته برق کنترل، شبیه سازی کامل مدل توپ و میله و کنترلر فازی، شبیه سازی مقاله ieee
پروژه رشته برق کنترل، شبیه سازی کامل مدل توپ و میله و کنترلر فازی، شبیه سازی مقاله ieee
پاورپوینت جامعه مبحث خوشه بندی
پاورپوینت جامعه مبحث خوشه بندی
 پاورپوینت حاضر با عنوان خوشه بندی در قالب 32 اسلاید به تشریح کامل سه الگوریتم خوشه بندی سلسله مراتبی، K-Means و C-Means Fuzzy پرداخته و برای درک بهتر این الگوریتم ها مثال هایی آورده شده است. بخشی از متن: تفاوت خوشه بندی با طبقه بندی این است که هیچ متغیر هدفی برای خوشه بندی وجود ندارد. خوشه ...
پاورپوینت حاضر با عنوان خوشه بندی در قالب 32 اسلاید به تشریح کامل سه الگوریتم خوشه بندی سلسله مراتبی، K-Means و C-Means Fuzzy پرداخته و برای درک بهتر این الگوریتم ها مثال هایی آورده شده است. بخشی از متن: تفاوت خوشه بندی با طبقه بندی این است که هیچ متغیر هدفی برای خوشه بندی وجود ندارد. خوشه ...